리눅스프로그래머를위한가이드










![[http]](/imgs/http.png) http://www.tldp.org/LDP/lpg/lpg.html http://www.tldp.org/LDP/lpg/lpg.html
Contents
1. 리눅스 운영체제 (The Linux operating system) ¶1991년 3월 Linus Benedict Torvalds는 자신의 AT 386 컴퓨터용으로 멀티태스킹 시스템인 Minix를 구입했다. 그는 그것을 활용하여 리눅스라 부르는 자신만의 멀티태스킹 시스템을 개발하였다. 1991년 9월 그는 인터넷 상의 Minix 사용자들에게 E-메일을 통해 첫번째 프로토타입(Prototype)을 발표했다. 이것이 리눅스 프로젝트의 기원이다. 그때부터 많은 프로그래머들이 리눅스를 지원하기 시작했다. 그들은 디바이스 드라이버를 추가하고, 응용프로그램을 개발하고 POSIX를 따르는 것을 목표로 했다. 오늘날 리눅스는 매우 강력해졌지만 가장 큰 장점은 공짜(FREE)라는 점이다. 다른 플랫폼으로 리눅스를 이식하는 작업이 진행중이다.
2. 리눅스 커널 (The Linux Kernel) ¶리눅스의 기본은 커널이다. 모든 라이브러리를 바꿔버리더라도, 리눅스 커널이 남아있는 한 리눅스이다. 커널은 디바이스 드라이버, 메모리 관리, 프로세스 관리와 통신 관리를 포함한다. 커널 해커들은 때때로 프로그래밍을 쉽게도 어렵게도 만드는 POSIX 가이드라인을 따른다. 당신의 프로그램이 새로운 리눅스 커널 위에서 다르게 동작한다면, 변화는 곧 새로운 POSIX 가이드라인이 구현되었을 확률이 크다. 리눅스 커널에 대한 프로그래밍 정보를 원한다면, 리눅스 커널 해커를 위한 가이드(The Linux Kernel Hacker's Guide)를 읽어라.
3. 리눅스 libc 패키지 (The Linux libc Package) ¶libc: ISO 8859.1, , YP 함수들, crypt 함수들, 기본적인 Shadow 루틴들 (기본적으로는 포함되지 않음), ... libcompat에 있는 호환성을 위한 기존의 루틴들 (기본적으로 수행되지 않음),영어,불어 또는 독어 에러 메세지들, libcourses에 있는 bsd 4.4 lite와 호환성 있는 화면 핸들링 루틴들, libbsd에 있는 bsd와 호환되는 루틴들, libtermcap에 있는 화면 핸들링 루틴들, libdbm에 있는 데이타베이스 관리 루틴들, libm에 있는 수학계산 루틴들, crt0.o???에 있는 프로그램 실행을 위한 항목, libieee???에 있는 바이트 sex 정보 (우스운 ???를 대신할 정보를 보내주세요.), libgmon에 있는 사용자 공간 프로파일링(Profiling). 리눅스 libc 개발자들 중 누군가가 이 장을 써 주기를 바랍니다. 지금 내가 말할 수 있는 것은 실행할 수 있는 형태인 a.out이 공유 라이브러리 만들기의 변화를 의미하는 elf(executable and linkable format)으로 바뀔 것이라는 것뿐이다. 현재는 두 형태(a.out과 elf)가 모두 지원된다.
crt0.o같은 몇몇은 특별한 예외적인 저작권의 영향을 받기도 하지만, 리눅스 libc 패키지의 대부분은 라이브러리 GNU Public 라이센스(License)의 영향을 받는다. 상업적인 이진 배포본은 정적 링크에 의한 실행에 제약이 있다. 동적 링크에 의한 실행은 특별히 예외이고 FSF의 Richard Stallman은 아래와 같이 말했다.
Section 5에 따라 실행시키는데 아무런 제약이 없이 만들어진 오브젝트 파일이 제공되는 라이브러리를 첨부하지 않는 동적 링크 실행파일의 배포는 명백히 허용되어야 한다고 본다. 그래서 나는 지금 그것을 허용하도록 결정할 것이다. 실제적인 LGPL의 보완은 내가 새버전을 만들고 확인할 때까지 기다려야만 할 것이다.
4. 시스템 호출 (System Calls) ¶시스템 호출은 일반적으로 운영체제(커널)가 하드웨어/시스템에 지정된 또는 특권이 있어야 하는 동작들을 수행토록 요청하는 것이다. 리눅스 1.2 에서는 140개의 시스템 호출들이 정의되어 있다. close()와 같은 시스템 호출은 리눅스 libc에 구현되어 있다. 이 구현은 종종 결국에는 syscall()를 호출하는 매크로의 호출을 포함한다. syscall()에 넘겨지는 파라미터는 필요한 아규먼트에 의해 추적되는 시스템 호출 번호이다. 실제의 시스템 호출 번호들은 <sys/syscall.h>이 새로운 libc에 의해 업데이트되는 동안 <linux/unistd.h>에서 찾을 수 있다. libc를 근간을 두지않는 새로운 호출이 나타나지 않는 한 syscall()를 사용할 수 있다. 예를 들면, 아래와 같이 syscall()를 사용하여 파일을 닫을 수 있다.(권장하지 않음) :
#include <syscall.h>
extern int syscall(int, ...); int my_close(int filedescriptor) { return syscall(SYS_close, filedescriptor); } i386 구조에서는 하드웨어 레지스터의 갯수때문에 시스템 호출 번호이외에 5개의 아규먼트로 시스템 호출이 제한된다. 또 다른 구조위에서 리눅스를 사용한다면 _syscall 매크로를 위해 하드웨어가 얼마나 많은 아규먼트를 지원하는지 또는 얼마나 많은 개발자의 선택이 지원되는지를 알아 보기위해 <asm/unistd.h>를 체크할 수 있다. 이러한 _syscall 매크로들은 syscall() 대신에 사용될 수 있지만, 이러한 매크로는 라이브러리에 이미 존재할런지 모르는 Full Function으로 확장되므로 추천할만하지 못하다.
#include <linux/unistd.h>
_syscall1(int, close, int, filedescriptor); _syscall1 매크로는 close() 함수와 같은 모습으로 확장된다. 그러므로 libc 안에 close()를 한,두번 그리고 프로그램 안에 한번 가진다. 시스템 호출이 실패하면 syscall() 이나 _syscall 매크로의 반환값은 -1이고 성공하면 0 이나 0보다 큰값을 갖는다. 시스템 호출이 실패했다면 무슨 일이 일어났는지 알기위해 전역변수인 errno를 살펴봐라.
BSD와 SYS V에서 사용할 수 있는 다음의 시스템 호출들은 리눅스에서 사용할 수 없다. :
audit(),auditon(),auditsvc(),fchroot(),getauid(),getdents(),getmsg(),mincore(), poll(),putmsg(),setaudit(),setauid().
5. "스위스 군용 칼"같은 ioctl (The "swiss army knife" ioctl) ¶ioctl은 input/output control을 의미하며 파일디스크립터(filedescriptor)를 가지고 캐릭터 디바이스(character device)를 조종하는데 사용된다. ioctl의 형태는 ioctl(unsigned int fd, unsigned intrequest, unsigned long argument)이다.
에러를 만나면 반환값은 -1이고 다른 시스템 호출과 같이 요청이 성공하면 0보다 크거나 같은 값을 갖는다. 커널은 특수 파일(special file)이나 일반 파일들(regular files)과 구분된다. 특수 파일(special file)은 주로 /dev나 /proc 디렉토리에서 찾을 수 있다. 이 파일들은 드라이버와의 인터페이스를 숨기고 있고 텍스트나 이진 데이타를 포함하는 실제(일반) 파일이 아니라는 점에서 일반 파일(regular file)과 다르다. 이러한 점은 유닉스의 철학이고 모든 파일에 대해 정상적으로 읽기/쓰기 동작의 사용을 허락한다. 그러나 특수 파일이나 일반 파일을 가지고 그 이상의 일을 하고자 한다면 ioctl를 가지고 할 수 있다. 일반 파일보다는 특수 파일에 대해 ioctl이 종종 더 많이 필요할테지만 일반 파일에 대해서도 ioctl의 사용이 가능하다.
6. 리눅스 프로세스간의 통신 (Linux Interprocess Communications) ¶추상적 개념:
IPC(interprocess communication facilities)에 대한 자세한 내용은 리눅스 운영체제에 기술 되어 있다.
6.1. 소개 (Introduction) ¶리눅스 IPC(Inter-process communication)은 여러 프로세스들이 다른 프로세스와 통신할 수 있는 방법을 제공한다. 리눅스 C 프로그래머들이 이용할 수 있는 IPC 방법에는 아래와 같은 몇가지가 있다.
6.2.1. 기본 개념 (Basic Concepts) ¶간단히 말해서, 파이프(Pipe)는 한 프로세스의 표준 출력(Standard output)을 다른 프로세스의 표준 입력(Standard input)으로 연결하는 방법이다. 파이프는 IPC툴 중 가장 오래된 것으로 유닉스 운영체제의 초기 단계부터 사용되어 왔다. 파이프는 프로세스간의 단방향(반이중,half-duplex) 통신의 한 방법을 제공한다.
이러한 특징은 유닉스 명령어 라인(유닉스 쉘)에서 조차 폭넓게 사용된다.
ls | sort | lp
위의 예는 ls의 출력을 sort의 입력으로 하고 sort의 출력을 lp의 입력으로 사용하기 위해 파이프(pipe)를 이용하였다. 자료는 파이프라인을 통해 왼쪽에서 오른쪽으로 이동하듯이, 반이중 파이프를 통해 움직인다.
우리들이 쉘 스크립트 프로그래밍에서 파이프를 아주 세심하게 사용한다해도, 커널 레벨에서 일어나는 일에 대해서는 생각하지 않고 사용한다.
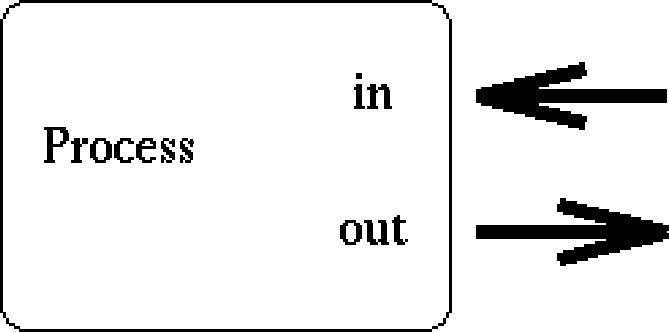
프로세스가 파이프를 만들 때, 커널은 파이프에 의해 사용될 두개의 파일 식별자(descriptor)를 준비한다. 한개의 식별자(descriptor)는 파이프(Write)의 입력 통로로 사용되고 다른 하나는 파이프(Read)로 부터 자료를 얻는데 사용된다. 이런 점에서 생성하는 프로세스는 자기자신과의 통신에만 파이프를 사용함으로 파이프는 거의 실질적으로 사용되지 않는다. 파이프가 만들어진 이후의 프로세스와 커널의 개념작용에 주의하라.
- 애석하게도 원문에서 다이어그램 그림이 빠져있음
위의 다이어그램으로 부터 식별자들이 서로 어떻게 연결되는지 쉽게 알 수 있다. 프로세스가 파이프(fd0)를 통해 자료를 보낸다면, fd1로 부터 자료를 얻을 수 (읽을 수) 있는 능력을 가지고 있다. 그렇지만 위의 극히 간단한 그림의 실재물은 매우 크다. 파이프가 처음에 프로세스와 자신을 연결하는 동안, 파이프를 통해 여행 중인 자료는 커널을 통해 움직인다. 특히 리눅스에서 파이프는 실제로 내부적으로 유효한 inode를 가지고 있음을 의미한다. 물론, 이 inode는 커널안에 존재하고 물리적인 파일 시스템에는 아무런 영향을 끼치지 않는다. 이러한 특징은 우리가 수동 I/O 문(handy I/O doors)을 열 수 있게 한다.
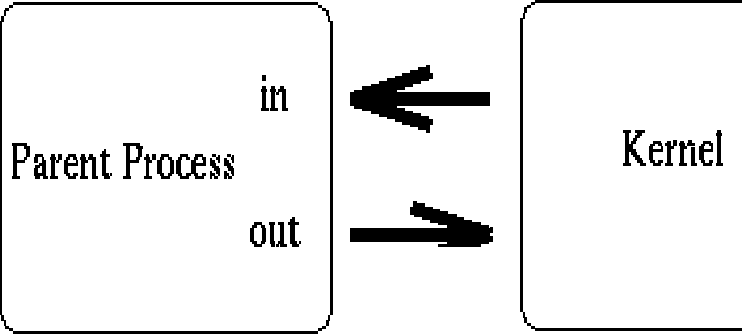
이러한 점에서 파이프는 명백히 쓸모없다. 결국, 우리가 오직 우리 자신에게 이야기하고자 한다면 왜 파이프 생성의 어려움을 가지고 가야만 하는가? 생성하는(creating) 프로세스는 전통적으로 자식 프로세스(child process)를 생성(fork)한다. 자식 프로세스는 부모로 부터 열려진 파일 식별자도 상속받았으므로 우리는 부모와 자식간의 멀티프로세스 통신을 위한 기초를 가지고 있다. 우리의 간단한 그림 수정본에 주의하라.
위와 같이 우리는 두 프로세스가 파이프 라인을 구성하는 파일 식별자에 접근할 수 있음을 볼 수 있다. 이번에는 중요한 결정을 내려야 한다. 어떤 방향으로 자료가 이동하기를 원하는가? 자식 프로세스가 부모에게 정보를 보낼 것인가 아니면 그 반대인가? 두 프로세스는 이러한 문제에 대해 상호 동의하고 있고 관계되어 있지 않은 파이프의 끝은 닫는다. 토론의 목적을 위해, 자식 프로세스가 어떤 작업을 수행하고 파이프를 통해 부모에게 정보를 전하는지를 살펴보자. 우리의 새롭게 고안된 그림은 다음과 같이 나타난다.:
현재 파이프라인의 구성은 완벽하다! 남아있는 일은 파이프의 사용뿐이다. 파이프에 직접적으로 접근하기 위해, 하위 레벨의 파일 I/O를 위해 사용되는 같은 기능의 시스템 호출을 사용할 수 있다. (파이프가 실제 내부적으로 유효한 inode로 표현됨을 기억하라)
파이프로 자료를 보내기 위해, 우리는 write() 시스템 호출을 사용하고 파이프로 부터 자료를 조회하기 위해 read()라는 시스템 호출을 사용한다. 하위 레벨의 파일 I/O 시스템 호출은 파일 식별자를 가지고 작업함을 기억하라! 어쨌든, 파이프에서 식별자를 가지고 작업하지 않는 lseek()와 같은 시스템 호출들을 기억하라.
6.2.2. C로 파이프 만들기 (Creating Pipes in C) ¶C 프로그래밍 언어로 파이프라인을 만드는 것은 간단한 쉘 예제보다는 많은 것을 포함한다. C로 간단한 파이프를 만들기 위해 pipe() 시스템 호출을 사용한다. 이것은 두 정수의 배열인 한개의 아규먼트(argument)를 가지며, 성공하면 배열은 파이프 라인을 위해 사용되는 새로운 두개의 파일 식별자를 갖는다. 파이프를 만들고 난 후, 프로세스는 전통적으로 새로운 프로세스를 낳는다. (자식은 열려진 파일 식별자를 상속받는다는 것을 기억하라)
SYSTEM CALL: pipe();
PROTOTYPE: int pipe(int fd[2]);
RETURNS: 성공시 0
-1 on error: errno = EMFILE (자유로운 식별자가 없다)
EMFILE (시스템 파일 테이블이 다 찼다)
EFAULT (fd 배열이 유효하지 않다)
NOTES: fd[0]는 읽기를 위해 준비되고, fd[1]은 쓰기를 위해 준비된다.
배열의 첫번째 정수(element 0)는 읽기를 위해 준비되고 열려지는 반면, 두번째 정수(element 1)는 쓰기를 위해 준비되고 열려진다. 시각적으로 말하면, fd1의 출력은 fd0를 위한 입력이 된다. 파이프를 통해 이동하는 모든 자료는 커널을 통해 이동함을 다시 말해둔다.
#include <stdio.h>
#include <unistd.h> #include <sys/types.h> main() { int fd[2]; pipe(fd); . . } C에서 배열의 이름은 첫번째 멤버의 포인터임을 기억하라. 위에서, fd는 &fd0와 같다. 파이프 라인을 만들고 난 후, 새로운 자식 프로세스를 생성(fork)한다.:
#include <stdio.h>
#include <unistd.h> #include <sys/types.h> main() { int fd[2]; pipe(fd); if((childpid = fork()) == -1) { perror("fork"); exit(1); } . . } 부모가 자식으로 부터 자료를 조회하기를 원한다면, fd1를 닫아야 하고 자식은 fd0를 닫아야 한다. 부모가 자식에게 자료를 보내고자 한다면, fd0를 닫아야 하고 자식은 fd1을 닫아야 한다. 부모와 자식간에 식별자를 공유하고 있으므로, 관계하고 있지 않는 파이프의 끝은 항상 닫혀져야만 한다. 기술적인 주의사항은 불필요한 파이프의 끝을 명백하게 닫지 않으면 EOF는 영원히 돌아오지 않는다는 것이다.
#include <stdio.h>
#include <unistd.h> #include <sys/types.h> main() { int^Ifd[2]; pid_t^Ichildpid; pipe(fd); if((childpid = fork()) == -1) { perror("fork"); exit(1); } if(childpid == 0) { /*자식 프로세스는 파이프의 입력 쪽을 닫는다*/ close(fd[0]); } else { /*부모 프로세스는 파이프의 출력 쪽을 닫는다*/ close(fd[1]); } . . } 앞에서 말했던 것처럼, 파이프라인을 만든 후에 파일 식별자는 일반 파일의 식별자처럼 취급된다.
/*****************************************************************************
리눅스 프로그래머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: pipe.c *****************************************************************************/ #include <stdio.h> #include <unistd.h> #include <sys/types.h> int main(void) { int fd[2], nbytes; pid_t childpid; char string[] = "Hello, world!\n"; char readbuffer[80]; pipe(fd); if((childpid = fork()) == -1) { perror("fork"); exit(1); } if(childpid == 0) { ^I^I/*자식 프로세스는 파이프의 입력 쪽을 닫는다*/ close(fd[0]); ^I^I/*파이프의 출력 쪽으로 "string"을 보낸다*/ write(fd[1], string, strlen(string)); exit(0); } else { ^I^I/*부모 프로세스는 파이프의 출력 쪽을 닫는다*/ close(fd[1]); ^I^I/*파이프로 부터 문자열을 읽는다*/ nbytes = read(fd[0], readbuffer, sizeof(readbuffer)); printf("Received string: %s", readbuffer); } return(0); } 종종 자식의 식별자는 표준 입력 또는 출력과 중첩된다. 자식은 표준 stream을 상속하는 다른 프로그램을 exec() 할 수 있다. dup() 시스템 호출을 살펴보자.:
SYSTEM CALL: dup();
PROTOTYPE: int dup( int oldfd );
RETURNS: 성공시 새로운 식별자
-1 on error: errno = EBADF (oldfd가 유효한 식별자가 아니다)
EBADF (newfd가 범위를 벗어났다)
EMFILE (프로세스에 대해 식별자가 너무 많다)
NOTES: 과거의 식별자는 닫혀지지 않는다. 두개가 상호 교환되어질 수 있다.
과거의 식별자와 새로 만들어진 식별자가 상호 교환되어질 수 있더라도, 전통적으로 표준 stream의 한쪽을 닫는다. dup() 시스템 호출은 새로운 식별자에게 아직 사용되지 않은 가장 작은 번호를 부여한다.
주의해서 보자:
.
. childpid = fork(); if(childpid == 0) { ^I^I/*자식의 표준 입력을 닫는다*/ close(0); ^I^I/*파이프의 입력 쪽을 표준입력으로 한다*/ dup(fd[0]); execlp("sort", "sort", NULL); . } 파일 식별자 0이 닫힌 후, dup()를 호출하여 파이프의 입력 식별자(fd0)를 표준 입력으로 복사한다. 정렬(sort) 프로그램과 자식의 텍스트 세그먼트(text segment)를 중첩시키기 위해 execlp()의 호출을 사용한다. 새롭게 exec된 프로그램들은 그들의 부모로 부터 표준 stream을 상속받으므로, 실제로 파이프의 입력 끝을 표준 입력처럼 상속받는다. 원래의 부모 프로세스가 파이프로 보내려는 것은 sort로 가게 된다.
dup2()라는 또 다른 시스템 호출을 사용할 수 있다. 이러한 특별한 호출은 유닉스 버전 7로 부터 시작되었고, BSD 버전에서도 수행되며 POSIX 표준에서도 필요하다.
SYSTEM CALL: dup2();
PROTOTYPE: int dup2( int oldfd, int newfd );
RETURNS: 성공시 새 식별자
-1 on error: errno = EBADF (oldfd가 유효한 식별자가 아니다)
EBADF (newfd가 범위를 벗어났다)
EMFILE (프로세스에 대해 식별자가 너무 많다)
NOTES: 과거의 식별자는 dup2()에 의해 닫힌다!
이런 특별한 호출을 사용하여 한개의 시스템 호출로 포장되어 있는 close 작업과 실제 식별자 복사 작업을 한다. 게다가, 작업의 원자화(atomic)가 허용되는데 이는 기본적으로 신호의 도착에 의해 작업이 중단되지 않음을 의미한다. 전체 동작은 신호의 발송을 위해 커널에게 통제권을 돌려주기 전에 일어난다. 프로그래머는 호출하기 전에 원래의 dup() 시스템 호출을 가지고 close() 작업을 수행해야만 한다. 그것은 그들 사이에서 경과되는 작은 시간의 양에 대한 다소의 약점을 가진 두개의 시스템 호출로 끝난다. 그 짧은 사이에 신호가 도착한다면, 시별자의 복사는 실패한다. 물론, dup2()는 이러한 문제를 해결했다.
살펴보자:
.
. childpid = fork(); if(childpid == 0) { /* Close stdin, duplicate the input side of pipe to stdin */ dup2(0, fd[0]); execlp("sort", "sort", NULL); . . } 6.2.3. 파이프 쉬운 방법! (pipes the Easy Way!) ¶앞의 두서없는 글들이 파이프를 만들고 사용하는 매우 무난한 방법처럼 보였다면, 또 다른 것이 있다.
LIBRARY FUNCTION: popen();
PROTOTYPE: FILE *popen ( char *command, char *type);
RETURNS: 성공시 새로운 파일 스트림(stream)
fork(),pipe()호출이 실패했을 때 널(NULL)
NOTES: 명령어("command")를 사용하여 파이프를 만들고 fork/exec를 수행한다.
이 표준 라이브러리 함수는 내부적으로 pipe()를 호출하여 반이중 파이프라인을 만든다. 쉘에서 자식 프로세스를 생성(fork)하고, 본 쉘(Bourne ahell)을 exec하고 "command" 아규먼트를 실행한다. 자료 흐름의 방향은 두번째 아뮤먼트인 "type"에 의해 결정된다. "read"이나 "write"에 대해 "r"이나 "w"가 될 수 있다. 두가지가 모두 될 수는 없다. 리눅스에서, 파이프는 "type"의 첫번째 글자에 의해 지정된 모드로 열려진다. 따라서, "rw"를 넘긴다면 읽기("read") 모드로 열려진다.
이 라이브러리 함수가 당신을 위해 까다로운 일을 수행하는 동안, 중요한 흥정(tradeoff)이 일어난다. pipe() 시스템 호출을 사용하고 fork/exec를 취급하는 것에 의해 당신은 잠시 통제권을 잃어버린다. 본 쉘이 직접 사용되므로, "command" 아규먼트 내에서 와일드 카드(wildcard)를 포함한 쉘 메타문자 확장(shell metacharacter expansion)이 가능하다.
popen()에 의해 만들어진 파이프는 pclose()로 닫아야만 한다. popen/pclose가 표준 파일 스트림 I/O 함수인 fopen(),fclose()와 매우 비슷하다는 것을 알았을 것이다.
LIBRARY FUNCTION: pclose();
PROTOTYPE: int pclose( FILE *stream );
RETURNS: wait4() 호출의 탈출 상태(exit status)
-1 스트림("stream")이 유효하지 않거나 wait4()가 실패했으면
NOTES: 파이프 프로세스가 종료되기를 기다렸다가 스트림을 닫는다.
pclose() 함수는 popen()에 의해 생성(fork)된 프로세스에 대해 wait4()를 수행한다. wait4()로부터 반환될 때, 파이프와 파일 스트림을 파괴한다. 일반적인 스트림에 기초한 파일 I/O에 대한 fclose() 함수와 동의어라 할 수 있다.
sort명령어로 파이프를 열어 문자열의 배열을 정렬처리하는 예제를 살펴보자:
/*****************************************************************************
리눅스 프로그램머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: popen1.c *****************************************************************************/ #include <stdio.h> #define MAXSTRS 5 int main(void) { int cntr; FILE *pipe_fp; char *strings[MAXSTRS] = { "echo", "bravo", "alpha", "charlie", "delta"}; ^I/*popen() 호출을 사용하여 단방향 파이프를 만든다*/ if (( pipe_fp = popen("sort", "w")) == NULL) { perror("popen"); exit(1); } ^I/*반복 처리*/ for(cntr=0; cntr<MAXSTRS; cntr++) { fputs(strings[cntr], pipe_fp); fputc('\n', pipe_fp); } ^I/*파이프를 닫는다*/ pclose(pipe_fp); return(0); } popen()는 자신의 명령을 수행하는데 쉘을 사용함으로, 모든 쉘 확장 문자들과 메타문자의 사용이 가능하다. 더군다나 redirection과 같은 보다 진보된 기술과 파이프의 출력조차 popen()에서 사용될 수 있다. 다음의 간단한 호출을 살펴보자:
popen("ls ~scottb", "r");
popen("sort > /tmp/foo", "w"); popen("sort | uniq | more", "w"); popen()의 또 다른 예인, 두개의 파이프(하나는 ls, 다른 하나는 sort)를 여는 작은 프로그램을 살펴보자:
/*****************************************************************************
리눅스 프로그램머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: popen2.c *****************************************************************************/ #include <stdio.h> int main(void) { FILE *pipein_fp, *pipeout_fp; char readbuf[80]; ^I/*popen() 호출을 사용하여 단방향 파이프를 만든다*/ if (( pipein_fp = popen("ls", "r")) == NULL) { perror("popen"); exit(1); } ^I/*popen() 호출을 사용하여 단방향 파이프를 만든다*/ if (( pipeout_fp = popen("sort", "w")) == NULL) { perror("popen"); exit(1); } ^I/*반복 처리*/ while(fgets(readbuf, 80, pipein_fp)) fputs(readbuf, pipeout_fp); ^I/*파이프를 닫는다*/ pclose(pipein_fp); pclose(pipeout_fp); return(0); } popen()의 마지막 예제를 위해, 넘겨받은 명령어와 파일명간의 파이프라인을 여는 일반적인 프로그램을 작성해 보자:
/*****************************************************************************
리눅스 프로그래머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: popen3.c *****************************************************************************/ #include <stdio.h> int main(int argc, char *argv[]) { FILE *pipe_fp, *infile; char readbuf[80]; if( argc != 3) { fprintf(stderr, "USAGE: popen3 [command] [filename]\n"); exit(1); } ^I/*입력 파일을 연다*/ if (( infile = fopen(argv[2], "rt")) == NULL) { perror("fopen"); exit(1); } ^I/*popen() 호출을 사용하여 단방향 파이프를 만든다*/ if (( pipe_fp = popen(argv[1], "w")) == NULL) { perror("popen"); exit(1); } ^I/*반복 처리*/ do { fgets(readbuf, 80, infile); if(feof(infile)) break; fputs(readbuf, pipe_fp); } while(!feof(infile)); fclose(infile); pclose(pipe_fp); return(0); } 다음의 예를 가지고 이 프로그램을 수행시켜보자:
popen3 sort popen3.c
popen3 cat popen3.c
popen3 more popen3.c
popen3 cat popen3.c | grep main
6.2.4. 파이프의 Atomic 동작 (Atomic Operations with Pipes) ¶원자화(Atomic)가 고려되어야 하는 동작들은 어떤 이유에서건 수행을 하는데 방해를 받아서는 않된다. 전체의 동작이 한번에 일어난다. POSIX 표준은 /usr/include/posix1_lim.h 파일에 파이프의 원자(Atomic) 동작을 위한 최대 버퍼의 크기를 명시하고 있다.:
#define _POSIX_PIPE_BUF 512
자동적으로 파이프로 부터 512바이트까지 쓰거나 읽을 수 있다. 사이에 걸쳐지는 것은 쪼개어 질 것이며, 원자화(Atomic)되지 않는다. 리눅스에서 원자화(Atomic)되는 동작의 한계는 "linux/limits.h" 파일에 정의되어 있다.:
#define PIPE_BUF 4096
보다시피, 리눅스는 POSIX에서 필요로 하는 최소한의 바이트를 수용한다. 파이프 동작의 원자화(Atomicity)는 한개 이상의 프로세스(FIFOS)가 포함될 때 중요하게 된다. 예를 들어 파이프에 쓰여지는 바이트의 수가 한개의 동작의 원자 한계(Atomic Limit)를 초과하거나 복수개의 프로세스가 파이프를 쓰고 있는 경우, 자료는 사이에 끼워 넣어지거나(interleaved) 내던져 질 것 이다(chunked). 바꿔 말하면, 한 프로세스가 쓰기를 수행하는 동안 다른 프로세스가 파이프라인에 자료를 넣을 수 있다는 것이다.
6.2.5. 반이중 파이프의 정리 (Note on half-duplex pipes) ¶
6.3.1. 기본 개념 (Basic Concepts) ¶이름을 가진 파이프는 대주분 일반 파이프와 같이 작업하지만, 몇가지 주목할만한 차이점이 있다.
6.3.2. FIFO 만들기 (Creating a FIFO) ¶이름을 가진 파이프(named pipe)를 방법에는 몇가지가 있다. 처음 두가지는 쉘로 부터 직접 만드는 것이다.
mknod MYFIFO p mkfifo a=rw MYFIFO 위의 두 명령어는 한기지 예외를 제외하고 동일한 동작을 수행한다. mkfifo 명령어는 파이프를 만든 후 FIFO 파일에 대해 직접 허가사항(permission)을 바
꾸기 위한 항목을 제공한다. mknod의 경우는 chmod 명령어의 빠른 호출이 필요할 것이다.
FIFO 파일은 긴 디렉토리 리스트(long directory listing)에서 보여지는 "p" 지시자에 의해 물리적인 파일 시스템에 재빨리 알려진다.
$ ls -l MYFIFO
prw-r--r-- 1 root root 0 Dec 14 22:15 MYFIFO|
파일명 다음에 있는 수직선("pipe sign")에 주목하라.
C로 FIFO를 만들기 위해, mknod() 시스템 호출을 사용할 수 있다.:
LIBRARY FUNCTION: mknod();
PROTOTYPE: int mknod( char *pathname, mode_t mode, dev_t dev);
RETURNS: 0 on success,
-1 on error: errno = EFAULT (pathname invalid)
EACCES (permission denied)
ENAMETOOLONG (pathname too long)
ENOENT (invalid pathname)
ENOTDIR (invalid pathname)
(see man page for mknod for others)
NOTES: Creates a filesystem node (file, device file, or FIFO)
man 페이지에 mknod()에 대한 보다 자세한 내용을 남길테지만, C로 만들어진 FIFO의 간단한 예를 살펴보자.:
mknod("/tmp/MYFIFO", S_IFIFO|0666, 0);
이 경우, "/tmp/MYFIFO" 파일은 FIFO 파일처럼 만들어 진다. 다음처럼 지정된 umask에 의해 영향을 받는다 하더라도 요청된 허가사항(permission)은 "0666"이다.:
final_umask = requested_permissions & ~original_umask
일반적인 방법은 일시적으로 umask 값을 공격하기 위해 umask() 시스템 호출을 사용하는 것이다.:
umask(0);
mknod("/tmp/MYFIFO", S_IFIFO|0666, 0); 게다가, 디바이스 파일을 만들고 있지 않다면 mknod()의 세번째 아규먼트는 무시된다. 이런 경우에는 디바이스 파일의 큰쪽과 작은 쪽의 번호를 지정해 주어야만 한다.
6.3.3. FIFO 동작 (FIFO Operations) ¶FIFO의 I/O 동작은 한개의 주요한 차이점을 제외하고 본질적으로 일반 파이프와 같다. "open" 시스템 호출이나 라이브러리 함수는 물리적으로 파이프의 채널을 여는데 사용되어져야 한다. 반이중 파이프에서는 파이프가 물리적인 파일 시스템이 아닌, 커널에 존재함으로 불필요하다. 예제에서 우리는 파이프를 fopen()으로 파일을 열고, fclose()로 닫는 스트림(stream)처럼 다룰 것 이다.
간단한 서버 프로세스를 살펴보자:
/*****************************************************************************
리눅스 프로그래머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: fifoserver.c *****************************************************************************/ #include <stdio.h> #include <stdlib.h> #include <sys/stat.h> #include <unistd.h> #include <linux/stat.h> #define FIFO_FILE "MYFIFO" int main(void) { FILE *fp; char readbuf[80]; ^I/*파이프가 존재하지 않으면 만든다*/ umask(0); mknod(FIFO_FILE, S_IFIFO|0666, 0); while(1) { fp = fopen(FIFO_FILE, "r"); fgets(readbuf, 80, fp); printf("Received string: %s\n", readbuf); fclose(fp); } return(0); } 디폴트로 FIFO는 차단됨으로, 컴파일한 후에 백그라운드로 server를 실행시켜라:
$ fifoserver&
잠시 FIFO의 차단 동작에 대해 말하겠다. 먼저, 서버에 대한 다음의 간단한 클라이언트 변환부(frontend)를 살펴보자:
/*****************************************************************************
리눅스 프로그래머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: fifoclient.c *****************************************************************************/ #include <stdio.h> #include <stdlib.h> #define FIFO_FILE "MYFIFO" int main(int argc, char *argv[]) { FILE *fp; if ( argc != 2 ) { printf("USAGE: fifoclient [string]\n"); exit(1); } if((fp = fopen(FIFO_FILE, "w")) == NULL) { perror("fopen"); exit(1); } fputs(argv[1], fp); fclose(fp); return(0); } 6.3.4. FIFO의 동작 차단 (Blocking Actions on a FIFO) ¶일반적으로 차단은 FIFO에서 발생한다. 바꾸어 말하면, FIFO가 읽기를 위해 열려져 있다면, 프로세스는 다른 프로세스들이 쓰기를 위해 열려고 할 때까지 차단(block)시킬 것이다. 이러한 동작은 반대로도 수행된다. 이러한 동작들을 원하지 않는다면, 디폴트 동작 차단 기능을 사용하지 않도록 open() 호출시에 O_NONBLOCK 플래그를 사용할 수 있다.
간단한 서버의 경우, 백그라운드로 밀어내고, 거기서 차단된 채로 남겨둔다. 또 다른 방법은 또 다른 가상의 콘솔로 뛰어들어 클라이언트 쪽을 실행시키고 수행결과를 앞,뒤로 전환시키는 것이다.
6.3.5. 잘 알려지지 않은 SIGPIPE 신호 (The Infamous SIGPIPE Signal) ¶마지막 정리로, 파이프는 읽기와 쓰기를 할 수 있다. 프로세스가 읽기가 안되는 파이프에 쓰려고 한다면, 커널로 부터 SIGPIPE 신호를 받게 된다. 이것은 두개 이상의 프로세스가 파이프라인에 포함되어 있을 때 필수적이다.
6.4.1. 기본적인 개념 (Fundamental Concepts) ¶시스템 V상에서 AT&T는 IPC 설비의 갖는 세가지 새로운 형태(메세지 큐(message queue), 세마퍼(semaphores), 공유 메모리(shared memory))를 소개했다. POSIX 위원회에서는 아직 이 세가지 설비에 대한 표준화를 마치지 못하고 있지만, 대부분의 구현들은 이들을 지원하고 있다. 더군다나 버클리(BSD)는 시스템 V 요소보다는 소켓을 IPC의 기초 형태로 사용한다. 뒷장에서 소켓에 대해 논하겠지만, 리눅스는 IPC의 두가지 형태(BSD와 System V)를 사용할 수 있다.
시스템 V IPC의 리눅스 구현은 Krishna balasubramanian(balasub@cis.ohio-state.edu)에 의해 기술되었다.
6.4.1.1. IPC 확인자 (IPC Identifiers) ¶각각의 IPC 객체(Object)은 그것과 연관된 유일한 IPC 확인자(Identifier)를 갖는다. "IPC 객체(object)"라고 함은 단일 메세지 큐(single message queue), 세마퍼 집합(semaphore set), 또는 공유 메모리 세그먼트(shared memory segment)를 말한다. IPC 객체에 대한 우일한 확인자는 커널 안에서 사용된다. 예를 들면, 특별한 공유 메모리 세그먼트에 접근하기 위해 그 세그먼트에 할당된 유일한 ID 값이 필요하다.
확인자의 유일성은 문제의 객체 타입(type)과 관계 있다. 이를 설명하기 위해, "12345"라는 수치 확인자를 가정하자. 같은 확인자를 같는 두개의 메세지 큐는 없으므로, 같은 수치 확인자를 가진 공유 메모리 세그먼트와 메세지 큐를 구별할 수 있는 가능성이 존재한다.
6.4.1.2. IPC 키 (IPC Keys) ¶유일한 ID를 얻기위해, 키(key)가 사용되어져야 한다. 키(key)는 클라이언트와 서버 프로세스간에 서로 동의되어야 한다. 이것은 응용프로그램을 위한 클라이언트/서버 체제를 구성하는 첫번째 단계를 의미한다.
당신이 누군가에게 전화를 하고자 할 때는 전화번호를 알고 있어야 한다. 게다가 전화 회사는 당신에게서 나가는 전화를 마지막 목적지까지 어떻게 중계할 것인지 알고 있어야 한다. 반대편이 전화에 응답해야 연결이 이루어 진다.
시스템 V IPC 설비의 경우, 전화는 사용되는 객체의 타입을 가지고 직접적인 관련이 있다. 전화 회사나 라우팅 방법(routing method)은 IPC 키(key)와 적접 연관되어 진다.
키는 응용프로그램에서 키값을 하드코딩함으로써 항상 같은 값을 가질 수 있다. 이것은 키가 이미 사용된 것일 수 있다는 단점이 있다. 종종 ftok() 함수는 클라이언트와 서버 모두에 의해 키값을 발생시키는데 사용된다.
LIBRARY FUNCTION: ftok();
PROTOTYPE: key_t ftok ( char *pathname, char proj );
RETURNS: new IPC key value if successful
-1 if unsuccessful, errno set to return of stat() call
ftok()로 부터 반환된 키값은 첫번째 아규먼트인 파일로 부터 inode 번호, minor 장치번호와 두번째 아규먼트인 한글자 프로젝트 확인자의 조합에 의해 발생한다. 이것은 유일성을 보장하지 않지만, 응용프로그램은 충돌을 체크하여 키를 다시 발생시킬 수 있다.
key_t mykey;
mykey = ftok("/tmp/myapp",'a'); 위의 예에서, 디렉토리 "/tmp/myapp"는 'a'라는 한글자와 조합된다. 또 다른 일반적인 예는 현재 디렉토리를 사용하는 것이다.
key_t mykey;
mykey = ftok(".",'a'); 사용되는 키 발생 알고리즘은 전적으로 응용프로그램 프로그래머의 마음에 달려 있다. 측정이 데드락(deadlocks), 경쟁상태의 방지등에 있는 한, 어떤 방법이든 나타날 수 있다. 예제의 목적은 ftok()의 사용에 있다. 만약 각 클라이언트 프로세스가 각기 유일한 홈 디렉토리로 부터 수행될 것이라고 가정한다면, 발생되는 키는 우리의 필요를 충족시켜야 한다.
얻어진 키값은 IPC 객체를 만들고 접근하기 위해 일련의 IPC 시스템 호출에서 사용된다.
6.4.1.3. ipcs 명령어 (The ipcs Command) ¶ipcs 명령어는 모든 시스템 V IPC 객체의 상태를 얻는데 사용할 수 있다. 이 툴의 리눅스 버전은 Krishna Balasubramanian에 의해 제작되었다.
ipcs -q: 메세지 큐(message queues)만을 보여준다. ipcs -s: 세마퍼(semaphore)만을 보여준다. ipcs -m: 공유 메모리(shared memory)만을 보여준다 ipcs --help: 부가적인 아규먼트(arguments) 디폴트로 세가지 객체의 종류가 모두 보여진다. 다음의 간단한 ipcs의 출력을 살펴보자:
--- Shared Memory Segments --- shmid owner perms bytes nattch status --- Semaphore Arrays --- semid owner perms nsems status --- Message Queues --- msqid owner perms used-bytes messages 0 root 660 5 1 여기서 우리는 "0"이라는 확인자(Identifier)를 가진 단일 메세지 큐(single message queue)를 볼 수 있다. 그것의 주인은 root 사용자이고, 660(-rw-rw--)의 8진 허가사항을 가지고 있다. 큐에는 한개의 메세지가 있고, 메세지의 총 크기는 5바이트이다.
ipcs 명령어는 IPC 객체에 대해 커널의 저장 조직을 엿볼 수 있는 가장 강력한 도구이다.
6.4.1.4. ipcrm 명령어 (The ipcrm Command) ¶ipcrm 명령어는 커널로 부터 IPC 객체를 제거하는데 사용된다. IPC 객체는 사용자 코드내에서 시스템 호출을 경우하여 제거될 수 있으며, 특히 개발 환경하에서 종종 수동으로 IPC 객체를 제거해야할 필요가 발생한다. 사용법은 간단하다.:
ipcrm <msg | sem | shm> <IPC ID> 지울 객체가 메세지 큐(msg)인지 세마퍼(sem)인지 공유 메모리(shm)인지를 간단히 지정한다. IPC ID는 ipcs 명령어로 구할 수 있다. 확인자는 같은 타입안에서만 유일함으로 객체의 타입을 지정해 주어야만 한다. (앞의 내용을 상기하라)
6.4.2.1. 기본 개념 (Basic Concepts) ¶메세지 큐는 커널의 주소 매겨진 공간(kernel's addressing space)안의 내부 연결 목록 (Internal linked list)이라는 말로 가장 잘 묘사될 수 있다. 메세지들은 차례대로 큐로 보내지고 여러가지 다른 방법으로 큐로 부터 조회된다. (물론) 각각의 메세지 큐는 IPC 확인자(identifier)에 의해 유일하게 확인된다.
6.4.2.2. 내부와 사용자 자료 구조 (Internal and User Data Structures) ¶시스템 V IPC와 같이 복잡한 주제를 충분히 이해하기 위한 열쇠는 한정된 커널 안에 존재하는 다양한 내부 자료 구조와 직접적으로 친해지는 것이다. 나머지들이 더 낮은 단계이 존재하고 있는 한, 이러한 구조에 대한 직접적인 접근은 가장 기본적인 동작에서 필요하다.
메세지 버퍼 (Message buffer)
가장 처음으로 만날 구조는 msgbuf 구조이다. 이 특별한 자료 구조는 메세지 자료를 위한 템플릿(template)라 생각할 수 있다. 프로그래머가 이러한 타입의 구조를 정의하여 사용하지 않는 한, msgbuf 타입의 구조를 실제적으로 이해하는 것은 필수적이다. linux/msg.h에 다음과 같이 선언되어 있다.:
/* message buffer for msgsnd and msgrcv calls */
/* msgsnd와 msgrcv 호출을 위한 메세지 버퍼 */ struct msgbuf { long mtype; /* type of message 메세지 타입 */ char mtext[1]; /* message text 메세지 내용 */ }; msgbuf 구조에는 두개의 멤버가 있다.:
mtype
양수로 표현되는 메세지 타입. 반드시 양수여야 한다.
mtext
메세지 자료 자체.
주어진 메세지에 타입을 부여하는 능력은 본질적으로 단일 큐에서의 다중(multiplex) 메세지들을 수용할 능력을 부여한다. 예를 들면, 클라이언트 프로세스들은 매직번호 (magic number)를 할당받을 수 있고 이것은 서버 프로세스로 부터 보내진 메세지들에 대해 메세지 타입처럼 사용될 수 있다. 서버는 자체적으로 몇몇의 다른 번호를 사용할 수 있고, 클라이언트는 그번호로 메세지를 보내기 위해 사용할 수 있다. 또 다른 시나리오에서는 응용프로그램은 에러 메세지에 대해 메세지 타입 '1'를 요청 메세지(request message)에 대해 메세지 타입 '2'를 표시할 수 있다. 이러한 가능성은 끝이 없다.
또 다른 방법은 대개 메세지 자료 요소 (mtext)에 매우 서술적인 이름을 부여하여 현혹되지 않도록 하는 것이다. 이 필드는 꼭 문자들의 배열이여야 할 필요는 없다. 어떤 형태의 어떤 자료이든 상관없다. 이 구조는 응용프로그램 프로그래머에 의해 재정의될 수 있으므로, 필드 그 자체만으로도 실제로 완전히 마음대로이다.
struct my_msgbuf {
long mtype; /* Message type 메세지 타입 */ long request_id; /* Request identifier 요청 확인자 */ struct client info; /* Client information structure 클라이언트 정보 구조 */ }; 전과 같은 메세지 타입을 볼 수 있지만, 구조의 나머지는 두개의 다른 요소로 바뀌었다. 그 중 하나는 또 다른 구조체(structure)이다! 이것이 메세지 큐의 장점이다. 커널은 자료가 무엇이든 자료의 변환을 일으키지 않는다. 어떤 정보든지 보내질 수 있다.
주어진 메세지의 최대 크기에 대한 내부적인 제한은 없다. 리눅스에서는 linux/msg.h에 다음과 같이 정의되어 있다.:
#define^IMSGMAX^I4056^I/* <= 4056 */^I/* max size if message (bytes) 메세지의 최대 크기 */
메세지는 길이가 4바이트(long)인 mtype 멤버를 포함하여 총 크기 4,056바이트보다 클 수 없다.
커널 msg 구조 (Kernel msg structure)
커널은 각각의 메세지를 msg 구조체의 모앙으로 큐안에 저장한다. 이것은 linux/msg.h에 다음과 같이 정의되어 있다.
/* 각 메세지에 대한 한개의 메세지 구조체 */
struct msg { struct^Imsg *msg_next;^I/* 큐에서의 다음 메세지 */ long msg_type; char *msg_spot; /* 메세지 내용 주소 */ short msg_ts; /* 메세지 내용 크기 */ }; msg_next
이것은 큐안에서의 다음 메세지에 대한 포인터이다. 이것은 커널의 주소매겨진 공간 (kernel addressing space)안에 한줄로 연결된 목록(singly linked list)처럼 저장되어 있다.
msg_type
이것은 사용자 구조체인 msgbuf에 할당된 메세지 타입이다.
msg_spot
메세지 본체의 시작점을 가리키는 포인터
msg_ts
메세지 내용 또는 본체의 길이
커널 msqid ds 구조 (Kernel msqid ds structure)
IPC 객체의 세가지 타입의 각각은 커널에 의해 유지되는 내부 자료 구조를 가진다. 메세지 큐에서는 msq_id 구조이다. 커널은 시스템 상에서 생성되는 모든 메세지 큐에 대해 이러한 구조를 하나씩 만들어 저장하고 관리한다. linux/msg.h에 다음과 같이 정의되어 있다.:
/* 시스템상에서 각 큐에 대한 msqid 구조 */
struct msqid_ds { struct ipc_perm msg_perm; struct msg *msg_first; /* first message on queue 큐의 처음 메세지*/ struct msg *msg_last; /* last message in queue 큐의 마지막 메세지*/ time_t msg_stime; /* last msgsnd time 마지막으로 msgsnd가 수행된 시간*/ time_t msg_rtime; /* last msgrcv time 마지막으로 msgrcv가 수행된 시간*/ time_t msg_ctime; /* last change time 마지막으로 change가 수행된 시간*/ struct wait_queue *wwait; struct wait_queue *rwait; ushort msg_cbytes; ushort msg_qnum; ushort msg_qbytes; /* max number of bytes on queue 큐의 최대 바이트 수*/ ushort msg_lspid; /* pid of last msgsnd 마지막으로 msgsnd를 수행한 pid*/ ushort msg_lrpid; /* last receive pid 마지막으로 받은 pid*/ }; 이 구조체의 대부분의 멤버들에 대해 관심을 갖는 일은 거의 없지만, 우리들의 여행을 완성시키기 위해 각각에 대해 간단히 설명하겠다.
msg_perm
ipc_perm 구조체의 하나로 linux/ipc.h에 정의되어 있다. 이것은 접근 허가사항(access permissions)과 큐의 생성자(creator)에 대한 정보(uid, etc)를 포함하는 메세지 큐의 허가사항 정보를 가지고 있다.
msg_first
큐의 첫번째 메세지와 연결되어 있다.(the head of the list)
msg_last
큐의 마지막 메세지와 연결되어 있다.(the tail of the list)
msg_stime
큐에 보내진 마지막 메세지의 시간 기록(Timestamp)
msg_rtime
큐로 부터 조회된 마지막 메세지의 시간 기록(Timestamp)
msg_ctime
큐에서 일어난 마지막 변화(change)의 시간 기록(Timestamp) (more on this later)
wwait
and
rwait
커널의 대기 큐(wait queue)를 가리키는 포인터. 메세지 큐에 있는 동작이 프로세스가 sleep 상태로 들어가는 것으로 간주할 때 사용된다. (i.e. 큐가 가득차서 프로세스가 열리기(opening)를 기다리고 있는 경우)
msg_qnum
현재 큐에 들어 있는 메세지의 갯수
msg_qbytes
큐 상의 최대 바이트 수
msg_lspid
마지막 메세지를 보낸 프로세스의 PID
msg_lrpid
마지막 메세지를 조회한 프로세스의 PID
커널 ipc perm 구조 (Kernel ipc perm structure)
커널은 ipc_perm 타입의 구조체 안에 IPC 객체의 허가사항(permission) 정보를 저장한다. 예를 들면, 앞에서 설명한 메세지 큐의 내부 구조에서는 msg_perm 멤버가 이런 타입이다. linux/ipc.h 안에 다음과 같이 선언되어 있다.:
struct ipc_perm
{ key_t key; ushort uid; /* owner euid and egid */ ushort gid; ushort cuid; /* creator euid and egid */ ushort cgid; ushort mode; /* access modes see mode flags below */ ushort seq; /* slot usage sequence number */ }; 위의 내용등은 모두 명백히 자기 해석적이다. 객체의 IPC 키를 가지고 저장되어 있는 것은 그 객체의 생성자(creator)와 주인(owner)에 대한 정보이다. (creator와 owner는 서로 다를 수 있음) 8진 접근 모드(the octal access mode) 또한 usigned short형태로 여기에 저장되어 있다. 마지막으로 slot usage sequence 번호가 끝에 저장되어 있다. 매번 IPC 객체는 시스템 호출 (destroyed)을 경유하여 닫힌다. 이 값은 시스템 안에 존재할 수 있는 IPC 객체의 최대수에 의해 증가된다. 이 값에 대해 우리가 관심을 가져야 하는가? 아니다.
NOTE:Richard Stevens의 UNIX Network Programming 125쪽에 이 주제에 대한 자세한 내용과 이것의 존재와 동작의 보안 이유등이 잘 설명되어 있다.
6.4.2.3. 시스템 호출:msgget() (SYSTEM CALL:msgget()) ¶새로운 메세지 큐를 만들기 위하여 또는 존재하는 큐에 접근하기 위하여, msgget() 시스템 호출이 사용된다.
SYSTEM CALL: msgget();
PROTOTYPE: int msgget ( key_t key, int msgflg );
RETURNS: 성공시 메세지 큐의 확인자(message queue identifier)
-1 on error: errno = EACCESS (접근권한이 없음)
EEXIST (큐가 이미 존재하여 만들 수 없음)
EIDRM (큐에 삭제 표시가 되어 있음)
ENOENT (큐가 존재하지 않음)
ENOMEM (큐를 만들기에 메모리가 부족함)
ENOSPC (최대 큐의 갯수를 초과함)
NOTES:
msgget()의 첫번째 아규먼트는 키값이다.(ftok()를 호출하여 넘겨받은 경우) 이 키값은 커널안에 있는 다른 메세지 큐들에 대해 키값이 존재하는지를 비교한다. 이때, 열기(open)나 접근(access) 동작은 msgflg 아규먼트의 내용에 따른다.
IPC_CREAT
커널안에 존재하는지를 확인한 후 큐를 만든다.
IPC_EXCL
IPC_CREAT가 사용될 때, 큐가 이미 존재하면 실패처리한다.
IPC_CREAT가 혼자 사용되면, msgget()는 새롭게 생선된 메세지 큐의 메세지 큐 확인자 (the message queue identifier)를 반환하거나, 같은 키값을 가지고 이미 존재하는 큐의 확인자를 반환한다. IPC_EXCL이 IPC_CREAT와 함께 사용되면, 새로운 큐가 만들어지거나 큐가 존재하면 -1를 가지며 호출에 실패한다. IPC_EXCL은 그 자체로는 쓸모가 없지만, IPC_CREAT와 함께 조합되어 접근하기 위한 존재하지 않는 큐를 여는(open) 것을 보장하는데 사용될 수 있다.
IPC 객체는 유닉스 파일 시스템상의 파일 허가사항의 기능과 비슷한 허가사항을 가지고 있으므로, 부가적인 8진 모드는 마스크 안에 OR될 것이다!
메세지 큐를 만들거나 열기 위한 빠른 wrapper 함수를 만들어 보자:
int open_queue(key_t keyval)
{ int qid; if((qid = msgget( keyval, IPC_CREAT | 0660 )) == -1) { return(-1); } return(qid); } 묵시적으로 0660의 허가사항(permission)을 사용함을 주목하라. 이 작은 함수는 메세지 큐 확인자 (int)를 반환하거나 에러시 -1을 반환한다. 키 값은 아규먼트로 넘겨져야만 한다.
6.4.2.4. 시스템 호출:msgsnd() (SYSTEM CALL:msgsnd()) ¶큐의 확인자를 가지고 있으면, 큐 상에서 여러가지 동작을 수행할 수 있다. 큐에 메세지를 전달하기 위해 msgsnd 시스템 호출을 사용한다.:
SYSTEM CALL: msgsnd();
PROTOTYPE: int msgsnd ( int msqid, struct msgbuf *msgp, int msgsz, int msgflg );
RETURNS: 0 on success
-1 on error: errno = EAGAIN (queue is full, and IPC_NOWAIT was asserted)
EACCES (permission denied, no write permission)
EFAULT (msgp address isn't accessable - invalid)
EIDRM (The message queue has been removed)
EINTR (Received a signal while waiting to write)
EINVAL (Invalid message queue identifier, nonpositive
message type, or invalid message size)
ENOMEM (Not enough memory to copy message buffer)
NOTES:
msgsnd의 첫번째 아규먼트는 이전의 msgget 호출에 의해 반환된 큐 확인자이다. 두번째 아규먼트인 msgp는 재선언되고 적재된 메세지 버퍼의 포인터이다. msgsz 아규먼트는 메세지 타입의 길이(4바이트)를 제외한 메세지의 바이트 크기를 포함한다.
msgflg 아규먼트는 0으로 지정될 수 있다.(ignored), or:
IPC_NOWAIT
메세지 큐가 가득 찼으면, 메세지는 큐에 씌여질 수 없고, 통제권(control)은 호출한 프로세스에게 돌아간다. 지정되지 않았으면, 호출한 프로세스는 메세지가 씌여질 수 있을 때까지 기다릴 것이다.
메세지를 보내는 또 다른 wrapper 함수를 만들어보자:
int send_message( int qid, struct mymsgbuf *qbuf )
{ int result, length; /* 길이는 기본적으로 구조체의 크기 - mtype의 크기 이다. */ length = sizeof(struct mymsgbuf) - sizeof(long); if((result = msgsnd( qid, qbuf, length, 0)) == -1) { return(-1); } return(result); } 이 작은 함수는 넘겨진 큐 확인자(qid)에 의해 고안된 메세지 큐에 넘겨진 주소(qbuf)에 있는 메세지를 보내려고 한다. 여기 우리가 지금까지 개발한 두개의 wrapper 함수를 활용한 간단한 코드가 있다.:
#include <stdio.h>
#include <stdlib.h> #include <linux/ipc.h> #include <linux/msg.h> main() { int qid; key_t msgkey; struct mymsgbuf { long mtype; /* 메세지 타입 */ int request; /* 작업 요청 번호 */ double salary; /* 직원의 급여 */ } msg; /* IPC 키 값을 발생시킨다 */ if(( qid = open_queue( mdgkey)) == -1) { perror("open_queue"); exit(1); } /* 임의의 테스트 자료를 메세지에 적재한다 */ msg.mtype = 1; /* 메세지 타입은 양수여야 한다 */ msg.request = 1; /* 자료 요소 #1 */ msg.salary = 1000.00; /* 자료 요소 #2 (나의 연간 급여) */ /* 뻥 날려보낸다 */ if((send_message( qid, &msg )) == -1) { perror("send_message"); exit(1); } } 메세지 큐를 만들고 연 후에, 메세지 버퍼에 테스트용 자료를 적재하는데 까지 했다. (이진 정보를 보내는 것에 대한 우리의 관점을 설명하기에는 문자 자료가 부족했음을 주목하라) 빠른 send_message의 호출은 단순히 메세지를 메세지 큐로 분배한다.
현재 우리는 큐에 메세지를 가지고 있으며, 큐의 상태를 보기위해 ipcs 명령어를 사용해라. 큐로 부터 실제로 메세지를 조회하기 위한 토론에 들어가 보자. 그런 일을 하기위해 msgrcv() 시스템 호출을 사용한다.:
SYSTEM CALL: msgrcv();
PROTOTYPE: int msgrcv ( int msqid, struct msgbuf *msgp, int msgsz, long mtype, int msgflg );
RETURNS: Number of bytes copied into message buffer
-1 on error: errno = E2BIG (Message length is greater than msgsz, no MSG_NOERROR)
EACCES (No read permission)
EFAULT (Address pointed to by msgp is invalid)
EIDRM (Queue was removed during retrieval)
EINTR (Interrupted by arriving signal)
EINVAL (msgqid invalid, or msgsz less than 0)
ENOMSG (IPC_NOWAIT asserted, and no message exists
in the queue to satisfy the request)
NOTES:
명백하게, 첫번째 아규먼트는 메세지 조회 처리를 하는 동안 사용될 큐를 지정하는데 사용된다. (일찍이 msgget를 호출하여 반환된 것이여야 함) 두번째 아규먼트(msgp)는 조회된 메세지를 저장할 메세지 버퍼 변수의 주소를 나타낸다. 세번째 아규먼트(msgsz)는 mtype 멤버의 길이를 제외한 메세지 버퍼 구조체의 크기를 나타낸다. 다시 한번 다음처럼 쉽게 계산될 수 있다.:
msgsz = sizeof(struct mymsgbif) - sizeof(long);
네번째 아규먼트(mtype)는 큐로 부터 조회될 메세지의 타입을 지정한다. 커널은 타입과 매칭되는 가장 오래된 메세지를 큐에서 찾을 것이고 msgp 아규먼트에 의해 지적된 주소에 그것을 복사하여 반환할 것이다. 한가지 특별한 경우가 존재한다. mtype 아규먼트에 0 값이 넘어오면, 타입을 무시하고 큐에서 가장 오래된 메세지를 반환한다.
IPC_NOWAIT가 flag처럼 넘겨지고 이용가능한 메세지가 없으면, 호출한 프로세스에게 ENOMSG를 반환한다. 그렇지 않으면, 호출한 프로세스는 msgrcv() 파리미터를 만족시키는 메세지가 큐에 도착할 때까지 기다린다. 클라이언트가 메세지를 기다리고 있는 동안 큐가 지워지면, EIDRM이 반환된다. 프로세스가 차단 상태에 있거나 메세지가 도착하기를 기다리는 동안 신호가 잡히면, EINTR가 반환된다.
큐로 부터 메세지를 조회하는 빠른 wrapper 함수를 점검해 보자.:
int read_message( int qid, long type, struct mymsgbuf *qbuf )
{ int result, length; /* 크기는 기본적으로 구조체의 크기 - mtype의 크기 이다. */ length = sizeof(struct mymsgbuf) - sizeof(long); if((result = msgrcv( qid, qbuf, length, type, 0)) == -1) { return(-1); } return(result); } 큐로 부터 메세지의 조회가 성공적으로 이루어지면, 큐 안에 있는 메세지는 파괴된다.
msgflg 아규먼트 안의 MSG_NOERROR 비트는 몇몇의 부가적인 능력을 제공한다. 물리적인 메세지 자료의 크기가 msgsz보다 크고 MSG_NOERROR가 사용되면, 메세지는 잘려져 오직 msgsz 바이트만큼만 반환된다. 일반적으로 msgrcv() 시스템 호출은 -1(E2BIG)을 반환하고 다음의 조회를 위해 큐 상에 메세지를 남겨 놓는다. 이런 동작은 우리의 요청에 만족하는 메세지가 도착했는지를 알아보기 위해 우리가 큐 안을 엿볼(peek) 수 있는 또 다른 wrapper 함수를 만들어 사용할 수 있다.
int peek_message( int qid, long type )
{ int result, length; if((result = msgrcv( qid, NULL, 0, type, IPC_NOWAIT)) == -1) { if(errno == E2BIG) return(TRUE); } return(FALSE); } 위에서 당신은 버퍼의 주소와 길이가 부족함을 알 것이다. 이런 특별한 경우에 있어서, 우리는 호출이 실패하기를 원한다. 그렇지만 우리는 우리가 요청한 타입과 일치되는 메세지가 존재하는지를 나타내는 E2BIG의 반환을 확인한다. wrapper 함수는 성공하면 TRUE를, 그렇지않으면 FALSE를 반환한다. 또한 이전에 언급했던 차단 동작(Blocking behavior)을 막기위한 IPC_NOWAIT flag의 사용에 주목하라.
6.4.2.5. 시스템 호출:msgctl() (SYSTEM CALL:msgctl()) ¶이전에 wrapper 함수들의 개발이 제공되었지만, 응용프로그램에서 메세지 큐를 만들고, 활용하기 위한 간단하고 우아한 접근방법을 가지고 있다. 주어진 메세지 큐와 연관된 내부 구조체를 직접 조종하기 위한 토론에 들어가 보자.
메세지 큐의 통제 동작을 수행하기 위해, msgctl() 시스템 호출을 사용한다.
SYSTEM CALL: msgctl();
PROTOTYPE: int msgctl ( int msgqid, int cmd, struct msqid_ds *buf );
RETURNS: 0 on success
-1 on error: errno = EACCES (No read permission and cmd is IPC_STAT)
EFAULT (Address pointed to by buf is invalid with IPC_SET and
IPC_STAT commands)
EIDRM (Queue was removed during retrieval)
EINVAL (msgqid invalid, or msgsz less than 0)
EPERM (IPC_SET or IPC_RMID command was issued, but
calling process does not have write (alter)
access to the queue)
NOTES:
내부 커널 자료 구조의 직접적인 조종은 밤 늦도록 재미를 가져다 줄 수도 있다. 불행스럽게도, 프로그래머들의 일부에게 남겨진 임무는 잡동사니인 IPC subsystem을 좋아한다면 재미로 분류되어 질 수 있다. 선택된 명령어 집합을 가지고 msgctl()를 사용하여, 재난을 일으킬 가능성이 적은 아이템을 조종할 수 있는 능력을 갖는다.
IPC_STAT
큐에서 msqid_ds 구조체를 조회하여 버퍼 아규먼트의 주소지에 저장한다.
IPC_SET
큐의 msqid_ds 구조체의 ipc_perm 멤버의 값을 지정한다. 버퍼 아규먼트로 부터 값을 취한다.
IPC_RMID
커널로 부터 큐를 제거한다.
메세지 큐에 대한 내부 자료 구조(msqid_ds)에 대해 언급했던 내용을 상기하자. 커널은 시스템에 존재하는 각각의 큐에 대해 이러한 구조체를 하나씩 가지고 있다. IPC_STAT 명령어를 사용하여 검사를 위해 이 구조체의 복사본을 조회할 수 있다. 내부 구조를 조회하여 넘겨진 주소로 복사하는 빠른 wrapper 함수를 살펴보자.:
int get_queue_ds( int qid, struct msgqid_ds *qbuf )
{ if( msgctl( qid, IPC_STAT, qbuf) == -1) { return(-1); } return(0); } 내부 버퍼로 복사할 수 없다면 호출한 함수에게 -1이 반환된다. 모든 것이 잘 되면, 0값이 반환되고 넘겨진 버퍼는 넘겨받은 큐 확인자(queue identifier,qid)에 의해 대표되는 메세지 큐에 대한 내부 자료 구조의 복사본을 갖는다.
큐의 내부 자료 구조체의 복사본을 가지고 있을 때, 어떤 특성을 조종할 수 있고, 그것들을 어떻게 변경시킬 수 있는가? 자료 구조 안에서 오직 수정할 수 있는 아이템은 ipc_perm 멤버이다. 이것은 주인(owner)와 생성자(creator)에 대한 정보는 물론, 큐의 허가사항도 포함한다. 그렇지만 수정될 수있는 ipc_perm 구조체의 멤버들은 mode,uid,gid 뿐이다. 주인(owner)의 user id, 주인(owner)의 group id, 큐의 접근 허가사항(access permission)을 바꿀 수 있다.
큐의 모드(mode)를 바꾸도록 고안된 wrapper 함수를 만들어 보자. 모드(mode)는 문자 배열로 넘겨져야 한다 (i.e. "660").
int change_queue_mode( int qid, char *mode )
{ struct msqid_ds tmpbuf; /* 내부 자료 구조의 현재 복사본을 조회한다 */ get_queue_ds( qid, &tmpbuf); /* 옛날의 기교를 사용하여 허가사항(permission)을 수정한다 */ sscanf(mode, "%ho", &tmpbuf.msg_perm.mode); /* 내부 자료 구조를 수정한다 */ if( msgctl( qid, IPC_SET, &tmpbuf) == -1) { return(-1); } return(0); } get_queue_ds wrapper 함수를 간단히 호출하여 내부 자료 구조의 현재 복사본을 조회한다. 연관된 msg_perm 구조의 mode 멤버를 변경하기 위해 sscanf()를 호출한다. 새 복사본을 내부 버전에 업데이트하기 전에는 아무런 변화도 일어나지 않는다. 이러한 일은 IPC_SET 명령어를 사용하여 msgctl()를 호출하여 수행할 수 있다.
주의! 큐의 허가사항을 변경할 수 있고, 그렇게 해서 본의아니게 스스로를 차단시킬 수 있다. 기억하라, 이러한 IPC 객체들은 적당히 제거하거나 시스템을 재부팅하지 않으면 없어지지 않는다. 따라서 ipcs를 가지고 큐를 볼 수 없다고 하여 존재하지 않는다는 것을 의미하지는 않는다.
이 점을 설명하기 위해, 다소 재미있는 일화를 소개하겠다. South Florida 대학에서 유닉스 내부를 가르치는 동안, 나는 아주 당황스럽고 어리둥절한 차단(Blocking)에 직면했다. 지난밤에 나는 일주일간의 수업에서 사용된 연구박업을 테스트하고 컴파일하기 위해 연구실 서버에 접속했다. 테스트를 하는 동안에 나는 코드안에 메세지 큐의 허가사항(permission)을 변경하는 타입을 만들었다는 사실을 깨달았다. 나는 간단한 메세지 큐를 만들었고, 아무런 사고없이 주고 받을 수 있는지를 테스트 했다. 그렇지만, 내가 큐의 모드를 "660"에사 "600"으로 수정하려고 했을 때, 내 자신의 큐로 부터 나 자신을 막아버리는 결과를 초래했다. 결과적으로 나는 내 소스 디렉토리의 같은 영역에서 메세지 큐 연구작업을 테스트 할 수 없었다. 내가 IPC 키를 만들기 위해 ftok() 함수를 사용했기에, 내가 큐에 접근하려고 할 때 나는 적당한 허가사항(permission)을 갖고 있지 못했다. 수업이 있는 아침에 결국 나는 지역 시스템 관리자에게 메세지 큐가 무엇인지와 왜 그가 나를 위해 ipcrm 명령어를 수행시켜야 하는지를 한시간동안 설명하고 접속을 끝냈다.
큐로부터 성공적으로 메세지를 받은 후, 메세지는 제거된다. 앞에서도 언급했던 것처럼, IPC 객체는 명백히 제거되거나 시스템을 재부팅하지 않는 한 시스템에 남아 있는다. 그러므로, 우리의 메세지 큐는 여전히 커널안에 존재하고 단일 메세지가 사라진 후에도 계속 사용할 수 있다. 메세지 큐의 생명 주기(life cycle)를 완성하기 위해 IPC_RMID 명령어를 사용하여 msgctl()를 호출에 의해 제거되어야 한다.:
int remove_queue( int qid )
{ if( msgctl( qid, IPC_RMID, 0) == -1) { return(-1); } return(0); } 이 wrapper 함수는 큐가 사고없이 제거되면 0을 반환하고 아니면 -1을 반환한다. 큐의 제거는 자연적으로 atomic하고 어떤 목적에서건 큐에 대한 어떤 일련의 접근도 형편없이 실패할 것이다.
6.4.2.6. msgtool:상호작용 메세지 큐 조종자 (An interactive message queue manipulator) ¶쉽게 이용할 수 있는 정확한 기술적인 정보를 갖는 직접적인 이익을 소수의 사람만이 가진다는 것은 부인할 수 없다. 어떤 요소들은 새로운 영역의 배움과 탐구를 위한 멋진 기교(mechanism)를 제공한다. 같은 맥락에서, 어떤 기술적인 정보를 따르는 실세계의 예제를 가지는 것은 프로세스를 배우는 것을 빨리하고 강화시킬 것이다.
지금까지, 언급된 유용한 예제들은 메세지 큐를 조종하는 wrapper 함수들이였다. 그것들은 매우 유용하지만, 어떤 의미에서는 보다 더 깊은 공부와 실험을 보장하지는 못하고 있다. 이런 점을 개선하기 위해, IPC 메세지 큐를 조종하기 위한 msgtool, 상호작용 명령어 라인 유틸리티(interative command line utility)를 사용할 수 있다. 이것은 확실히 교육 강화를 위한 적당한 도구로서의 기능을 하지만, 표준 쉘 스크립트를 경유하여 메세지 큐 기능을 제공하는 것에 의해 실 세계의 과제에 직접 적용할 수는 없다.
백그라운드 (Background)
msgtool 프로그램은 명령어 라인의 아규먼트에 의해 동작이 결정된다. 이것은 쉘 스크립트로 부터 호출되어질 때, 매우 유용하게 사용될 것이다. 큐를 만들고 메세지를 보내고 조회하고 큐의 허가사항을 바꾸고 끝으로 제거하는 모든 능력이 제공된다. 현재, 본문 상의 메세지를 보내는데 허용되는 데이타로는 문자 배열을 사용한다. 부가적인 자료 타입을 용이하게 바꾸는 것은 독자들의 과제로 남겨져 있다.
명령어 라인 문법 (Command Line Syntax)
메세지 보내기 (Sending Messages)
msgtool s (type) "text" 메세지 조회하기 (Retrieving Messages)
msgtool r (type) 허가사항 바꾸기 (Changing the Permissions(mode))
msgtool m (mode) 큐 지우기 (Deleting a Queue)
msgtool d 예제 (Examples)
msgtool s 1 test msgtool s 5 test msgtool s 1 "This is a test" msgtool r 1 msgtool d msgtool m 660 소스 (The Source)
다음은 msgtool 사용을 위한 소스 코드이다. 시스템 V IPC를 지원하는 최신의 커널 개정판에서 깨끗이 컴파일되어야 한다. 재작성(rebuild)시 커널에서 시스템 V IPC를 사용할 수 있는지 확인하라.
한편으로, 이 유틸리티는 어떤 동작이 요청되든지에 상관없이 메세지 큐가 존재하지 않으면 메세지 큐를 만들 것이다.
NOTE: 이 툴은 IPC 키 값을 발생시키기위해 ftok()함수를 사용함으로, 디렉토리 충돌을 만날지 모른다. 스크립트 내의 어느 한지점에서 디렉토리를 바꾼다면, 아마도 동작하지 않을 것이다. 또 다른 해결책은 msgtool안에 "/tmp/msgtool/"과 같이 보다 절대적인 경로(path)를 하드코딩하거나 조작상(operational)의 아규먼트에 따라, 명령어 라인상에서 넘겨진 경로(path)를 사용토록 허락하는 것이다.
/*****************************************************************************
리눅스 프로그래머를 위한 가이드 - 6장 에서 발췌 (C)opyright 1994-1995, Scott Burkett ***************************************************************************** MODULE: msgtool.c ***************************************************************************** 시스템 V 스타일의 메세지 큐를 사용하기 위한 명령어 라인 툴 *****************************************************************************/ #include <stdio.h> #include <stdlib.h> #include <ctype.h> #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #define MAX_SEND_SIZE 80 struct mymsgbuf { long mtype; char mtext[MAX_SEND_SIZE]; }; void send_message(int qid, struct mymsgbuf *qbuf, long type, char *text); void read_message(int qid, struct mymsgbuf *qbuf, long type); void remove_queue(int qid); void change_queue_mode(int qid, char *mode); void usage(void); int main(int argc, char *argv[]) { key_t key; int msgqueue_id; struct mymsgbuf qbuf; if(argc == 1) usage(); ^I/* ftok() 호출을 통해 유일한 키를 만든다 */ key = ftok(".", 'm'); ^I/* 필요하다면 큐를 만들고 연다 */ if((msgqueue_id = msgget(key, IPC_CREAT|0660)) == -1) { perror("msgget"); exit(1); } switch(tolower(argv[1][0])) { case 's': send_message(msgqueue_id, (struct mymsgbuf *)&qbuf, atol(argv[2]), argv[3]); break; case 'r': read_message(msgqueue_id, &qbuf, atol(argv[2])); break; case 'd': remove_queue(msgqueue_id); break; case 'm': change_queue_mode(msgqueue_id, argv[2]); break; default: usage(); } return(0); } void send_message(int qid, struct mymsgbuf *qbuf, long type, char *text) { ^I/* 큐에 메세지를 보낸다 */ printf("Sending a message ...\n"); qbuf->mtype = type; strcpy(qbuf->mtext, text); if((msgsnd(qid, (struct msgbuf *)qbuf, strlen(qbuf->mtext)+1, 0)) ==-1) { perror("msgsnd"); exit(1); } } void read_message(int qid, struct mymsgbuf *qbuf, long type) { ^I/* 큐로 부터 메세지를 읽는다. */ printf("Reading a message ...\n"); qbuf->mtype = type; msgrcv(qid, (struct msgbuf *)qbuf, MAX_SEND_SIZE, type, 0); printf("Type: %ld Text: %s\n", qbuf->mtype, qbuf->mtext); } void remove_queue(int qid) { ^I/* 큐를 지운다 */ msgctl(qid, IPC_RMID, 0); } void change_queue_mode(int qid, char *mode) { struct msqid_ds myqueue_ds; ^I/* 현재 정보를 읽는다 */ msgctl(qid, IPC_STAT, &myqueue_ds); ^I/* 모드를 읽어와 바꾼다 */ sscanf(mode, "%ho", &myqueue_ds.msg_perm.mode); ^I/* 모드를 수정한다 */ msgctl(qid, IPC_SET, &myqueue_ds); } void usage(void) { fprintf(stderr, "msgtool - A utility for tinkering with msg queues\n"); fprintf(stderr, "\nUSAGE: msgtool (s)end \n"); fprintf(stderr, " (r)ecv \n"); fprintf(stderr, " (d)elete\n"); fprintf(stderr, " (m)ode \n"); exit(1); } It's seems that this document is rather too old... Ex) poll() system call has been supported in Linux for long time.
|
He who has a shady past knows that nice guys finish last. 
|