아주 중요한 상업적인 프로그램들이 인터넷으로 전환하게 되면서 고가용성의 서비스를 제공하는 것이 아주 중요해지고 있다. 클러스터링 시스템을 구성하는 한가지 이점은 하드웨어와 소프트웨어에 여유분이 생긴다는 것이다. 노드나 대몬의 장애를 감지해 그 즉시 시스템을 재구성해서 작업 부하를 클러스터의 다른 노드로 이전하는 방식으로 고가용성의 서비스를 제공할 수 있다.
실제로 고가용성은 아주 광범위한 분야이다. 훌륭한 고가용성 시스템은 신뢰성있는 그룹간 통신 서브 시스템, 멤버쉽 관리, quoram 서브 시스템, 동시 제어 서브 시스템등으로 구성될 것이다. 여러 가지 방법이 있을 수 있지만 우리는 현재 매우 가용성이 높은 LVS 시스템을 구축하기 위해 현재 존재하는 소프트웨어를 사용할 수 있다. 고가용성의 LVS 시스템을 구성하는 데는 여러 가지 방법이 있을수 있는데 이 글을 읽는 분들만의 방법이 있는 경우에는 알려주면 좋겠다. 다음에 두가지 해결책을 소개하는데 참고로만 보자.
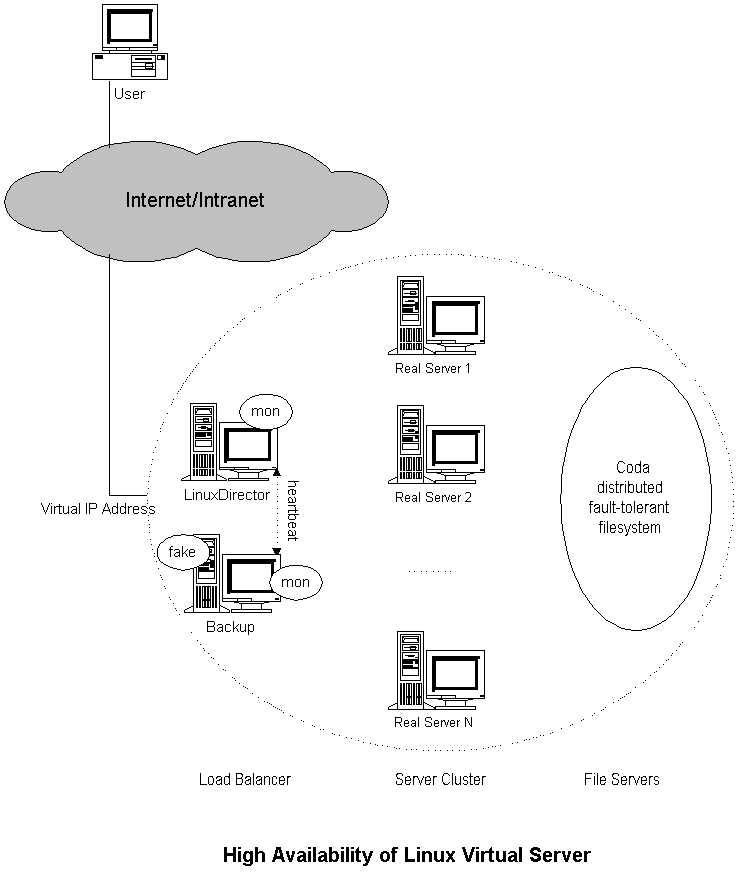
"mon", "heartbeat" , "fake" , "coda" 소프트웨어를 이용해 고가용성의 가상 서버를 구축할 수 있다. "mon"은 네트웍 서비스의 가용성과 서버 노드를 모니터링하는데 사용하는 범용 자원 모니터링 시스템이다. "hearbeat"는 시리얼 라인과 UDP 신호(hearbeat)를 이용해 두 노드간에 서버의 상황을 확인한다. fake는 ARP 속이기(spoofing)을 이용해 IP를 이전하는 소프트웨어이다. 다음의 그림을 통해 리눅스 가상 서버의 고가성을 확인해보자.
서버의 장애는 다음과 같이 제어가 된다: mon 대몬이 부하분산서버에서 수행되면서 클러스터의 서비스 대몬과 서버 노드를 모니터링한다. fping.monitor는 매 t 초마다 서버 노드가 살아있는지 감지하도록 구성하고, 관련된 서비스 모니터를 통해 매 m초마다 노드의 서비스 대몬을 감지하도록 구성을 한다. 예를 들어 http.monitor는 http 서비스를 점검하는데 사용할 수 있고 ftp 서비스에는 ftp.monitor 를 사용할 수 있다. 서비스 노드나 대몬의 상태(up/down)를 감지해서 리눅스 가상 서버 테이블에 규칙을 추가, 삭제하는 경보를 작성한다. 그래서 부하분산서버에서 서비스 대몬이나 서비스의 장애를 자동으로 기록하고 장애가 회복되었을 경우 서비스를 원상태로 돌릴 수 있다.
이제, 부하분산서버가 전체 시스템에서 유일한 장애 지점(single failure point)이 된다. 주부하분산서버의 장애를 감추기 위해 백업용 부하분산서버를 설정해야한다. "fake" 소프트웨어를 이용해 부하분산서버에서 장애가 발생할 경우 부하분산서버의 IP 주소를 백업 서버로 이전한다. "heatbeat" 코드를 이용 부하분산서버의 상태를 감지하고 백업서버에서 "fake" 를 가동시키거나 중지시킬 수 있다. 주서버와 백업서버에서 두 개의 heatbeat 대몬을 가동시키며, 주기적으로 시리얼 라인을 통해 서로가 "나 살아있어요~"라는 메시지를 주고 받는다. 백업서버에서 정의된 시간동안 주서버에서 "나 살아있어요"라는 메시지를 듣지 못하면, 부하 분산 서비스를 계속 제공하기 위해 가상 IP 주소를 이전하도록 fake를 활성화시킨다. 나중에 다시 "나 살아있어요"란 메시지를 받으면 가상 IP 주소를 해제하기 위해 fake를 중지시킨다.
그렇지만, 주부하분산서버의 장애이전이나 IP 이전을 하게 되면 해쉬 테이블의 이미 성립된 접속에 대해서는 수행을 하지 못하게 되며 클라이언트쪽에서 요구를 다시 보내야한다.
Coda는 장애-감내 분산 파일 시스템으로 Andrew 파일 시스템의 자손이라고 볼 수 있다. (** Andrew file system 은 IBM에서 나온 파일 시스템의 한 종류입니다. 코다 파일시스템의 경우 현재 계속 개발이 되고 있으므로 안정성에 대해서는 확신하기가 힘들 것 같습니다.) 서버의 내용을 코다 파일 시스템에 저장하면 가용성도 높아지고 관리하기에도 편리해질 것이다.
(** 용어가 많이 헷갈릴 것이다. Fault-tolerence 란 장애감내라고 하며 하드웨어의 특정한 부분에 장애가 생겨도 계속 서비스를 할 수 있는 것을 말한다. 보통 핫스왑 디스크, 핫스왑 냉각팬, 핫스왑 파워 등이 이에 해당하며 Redundant 요소이다. Failover란 장애극복이라고 하며 장애가 생길 경우 그 장애를 극복하고 서비스를 계속 하는 것이다. 클러스터링 구성이 장애극복을 위한 방법중의 하나이다.)
다음의 예는 다이렉트 라우팅을 이용한 매우 가용성 높은 가상 웹서버를 설정한 경우이다.
실제 서버의 장애극복
"mon"을 이용해 클러스터에서 서비스 대몬과 서버 노드를 모니터링한다. 예를 들어 fping.monitor는 서버 노드를 모니터링하는데 사용하며, http 서비스를 점검하기 위해 http.monitor를 사용할 수 있고 ftp 서비스에는 ftp.monitor를 사용할 수 있다. 서버 노드나 대몬이 down/up 되었을 경우 가상 서버 테이블의 규칙을 추가, 삭제하는 경고를 작성해야한다. lvs.alert 라는 다음의 예제는 가상 서비스(IP:Port)와 실제 서버의 서비스 포트를 인자(parameter)로 받는다.
#!/usr/bin/perl
#
# lvs.alert - Linux Virtual Server alert for mon
#
# It can be activated by mon to remove a real server when the
# service is down, or add the server when the service is up.
#
#
use Getopt::Std;
getopts ("s:g:h:t:l:P:V:R:W:F:u");
$ipvsadm = "/sbin/ipvsadm";
$protocol = $opt_P;
$virtual_service = $opt_V;
$remote = $opt_R;
if ($opt_u) {
$weight = $opt_W;
if ($opt_F eq "nat") {
$forwarding = "-m";
} elsif ($opt_F eq "tun") {
$forwarding = "-i";
} else {
$forwarding = "-g";
}
if ($protocol eq "tcp") {
system("$ipvsadm -a -t $virtual_service -r $remote -w $weight $forwarding");
} else {
system("$ipvsadm -a -u $virtual_service -r $remote -w $weight $forwarding");
}
} else {
if ($protocol eq "tcp") {
system("$ipvsadm -d -t $virtual_service -r $remote");
} else {
system("$ipvsadm -d -u $virtual_service -r $remote");
}
};lvs.alert 파일은 /usr/lib/mon/alert.d 디렉토리에 둔다. mon 설정 파일(/etc/mon/mon.cf 또는 /etc/mon.cf)을 이용해 클러스터에서 http 서비스와 서버를 모니터링하도록 설정할 수 있다. 다음 예를 보자.
#
# The mon.cf file
#
#
# global options
#
cfbasedir = /etc/mon
alertdir = /usr/lib/mon/alert.d
mondir = /usr/lib/mon/mon.d
maxprocs = 20
histlength = 100
randstart = 30s
#
# group definitions (hostnames or IP addresses)
#
hostgroup www1 www1.domain.com
hostgroup www2 www2.domain.com
#
# Web server 1
#
watch www1
service http
interval 10s
monitor http.monitor
period wd {Sun-Sat}
alert mail.alert wensong
upalert mail.alert wensong
alert lvs.alert -P tcp -V 10.0.0.3:80 -R 192.168.0.1 -W 5 -F dr
upalert lvs.alert -P tcp -V 10.0.0.3:80 -R 192.168.0.1 -W 5 -F dr
#
# Web server 2
#
watch www2
service http
interval 10s
monitor http.monitor
period wd {Sun-Sat}
alert mail.alert wensong
upalert mail.alert wensong
alert lvs.alert -P tcp -V 10.0.0.3:80 -R 192.168.0.2 -W 5 -F dr
upalert lvs.alert -P tcp -V 10.0.0.3:80 -R 192.168.0.2 -W 5 -F drLVS/NAT에서 목적지 포트가 다르면 "lvs.alert -V 10.0.0.3:80 -R 192.168.0.3:8080" 와 같은 식으로 lvs.alert의 매개변수를 설정해야한다는 것을 기억하자.
이제 부하분산서버에서 자동으로 서비스 대몬이나 서버의 장애를 감출 수 있고 다시 정상적으로 가동되는 경우 원상태로 회복할 수 있다.
부하분산서버의 장애극복
부하분산서버가 유일한 장애 지점(single failure point)이 되는 것을 방지하기 위해 백업용 부하분산서버를 설정해야하고 주기적으로 서로 살아 있다는 신호를 주고받도록 해야한다. heartbeat 패키지에 들어있는 GettingStarted 문서를 읽어보기를 바라며 2 노드의 heartbeating 시스템 설정은 간단한 편이다.
예를 들어, 다음과 같은 주소를 가진 두 개의 부하분산서버가 있다고 가정해보자.
lvs1.domain.com (primary) |
10.0.0.1 |
lvs2.domain.com (backup) |
10.0.0.2 |
www.domain.com (VIP) |
10.0.0.3 |
lvs1.domain.com 과 lvs2.domain.com 에 heartbeat를 설치한후 다음과 같이 간단하게 /etc/hd.d/ha.conf를 만들면 된다.
# # keepalive: how many seconds between heartbeats # keepalive 2 # # deadtime: seconds-to-declare-host-dead # deadtime 10 # hopfudge maximum hop count minus number of nodes in config hopfudge 1 # # What UDP port to use for udp or ppp-udp communication? # udpport 1001 # What interfaces to heartbeat over? udp eth0 # # Facility to use for syslog()/logger (alternative to log/debugfile) # logfacility local0 # # Tell what machines are in the cluster # node nodename ... -- must match uname -n node lvs1.domain.com node lvs2.domain.com
/etc/ha.d/haresources 파일은 다음과 같다:
lvs1.domain.com 10.0.0.3 lvs mon
/etc/rc.d/init.d/lvs 는 다음과 같다:
#!/bin/sh
#
# You probably want to set the path to include
# nothing but local filesystems.
#
PATH=/bin:/usr/bin:/sbin:/usr/sbin
export PATH
IPVSADM=/sbin/ipvsadm
case "$1" in
start)
if [ -x $IPVSADM ]
then
echo 1 > /proc/sys/net/ipv4/ip_forward
$IPVSADM -A -t 10.0.0.3:80
$IPVSADM -a -t 10.0.0.3:80 -r 192.168.0.1 -w 5 -g
$IPVSADM -a -t 10.0.0.3:80 -r 192.168.0.2 -w 5 -g
fi
;;
stop)
if [ -x $IPVSADM ]
then
$IPVSADM -C
fi
;;
*)
echo "Usage: lvs {start|stop}"
exit 1
esac
exit 0
최종적으로 모든 파일이 lvs1 과 lvs2 노드에 생성되었는지 확인하고 각자 환경에 맞게 설정을 변경한다음 두 노드에서 heartbeat 대몬을 시작하자.
"fake" (IP takeover by Gratuitous Arp)는 이미 heartbeat 패키지에 포함되어 있으므로 "fake"를 별도로 설정할 필요는 없다. lvs1.domain.com 노드에 장애가 생겼을 경우 lvs2.domain.com에서 lvs1.domain.com 의 모든 haresoures를 이전받을 것이다. 예를 들어 Gratuitous ARP를 이용 10.0.0.3 주소를 이전받고 /etc/rc.d/init.d/lvs 와 /etc/rc.d/init.d/mon 스크립트를 실행할 것이다. lvs1.domain.com이 되돌아올 경우 lvs2 는 HA 자원을 해제하고 lvs1에서 다시 그 자원을 이전받는다.
Jacob Rief이 작성한 ldirectord (Linux Director Daemon)는 실제 서버의 서비스를 모니터링하는 stand-alone 대몬으로 현재 http와 https 서비스를 지원한다. 설치하기 간편하고 heartbeat 코드와 잘 작동한다. ldirectord 프로그램은 ipvs tar 안에 있는 contrib 디렉토리에서 찾을 수 있다. 또는 가장 최신 버전의 heartbeat CVS 저장소를 확인해보자. 이에 대한 모든 정보는 'perldoc ldirectord'를 보자. 훌륭한 프로그램을 작성해준 Jacob Rief에 감사의 마음을 전한다.
mon에 비해 ldirectord 가 가지고 있는 장점은 다음과 같다:
node1 IPaddr::10.0.0.3 ldirectord::www ldirectord::mail
어째되었든 ldirectord를 수동으로 시작하거나 중지시킬 수 있다. 백업용 부하분산서버없이도 당신의 LVS 클러스터에 이 프로그램을 사용할 수 있다.
mon+heartbeat+fake+coda 해결책에서 소개한 예에서, /etc/ha.d/www.cf를 다음과 같이 설정할 수 있다:
#
# The /etc/ha.d/www.cf for ldirectord
#
# the number of second until a real server is declared dead
timeout = 10
# the number of second between server checks
checkinterval = 10
#
# virtual = x.y.z.w:p
# protocol = tcp|udp
# scheduler = rr|wrr|lc|wlc
# real = x.y.z.w:p gate|masq|ipip [weight]
# ...
#
virtual = 10.0.0.3:80
protocol = tcp
scheduler = wlc
real = 192.168.0.1:80 gate 5
real = 192.168.0.2:80 gate 5
request = "/.testpage"
receive = "test page"/etc/ha.d/haresources 파일은 다음과 비슷할 것이다:
lvs1.domain.com IPaddr::10.0.0.3 ldirectord::www
각 웹 서버의 DocumentRoot 디렉토리에 .testpage 파일을 생성해야한다.
echo "test page" > .testpage
주서버와 백업서버에서 heartbeat 대몬을 시작하자. 잘못된 부부이 있다면, /var/log/ha-log 와 /var/log/ldirector.log 파일을 제각각 저검해야한다.
HighAvailability.html,v 1.3 2000/01/11 14:00:52
wensong Exp $
Created on: 1998/12/5